

How To Set Up A Relational Database
How to design an effective relational database
A well-designed relational database will ensure your team's data is accurate, consequent, and reliable. Get the most use out of your database with these design tips.
If yous need to streamline your team's operations, ensure that multiple teams in your org are working from a unmarried source of truth, maintain a canonical inventory, or perform any other data-related responsibility, your team can benefit from a relational database.
Big and minor organizations alike utilize relational databases to more than efficiently store, manage, and analyze critical information, for purposes every bit disparate as customer relationship management, content product, product planning, UX research, and many more.
Not all relational databases are created equal, however. A poorly designed database might make it more difficult to access the data that yous need or jeopardize the accuracy of your information; in contrast, a well-designed database provides several benefits:
- You can avoid redundant, duplicate, and invalid data. Problematic data tin undermine the validity of your database, but yous can design your relational database to minimize the risks posed by low-quality data.
- You lot can avoid situations where you are missing required information. If you tin identify ahead of time which types of data are most disquisitional to your workflow, you can structure your database in such a manner that it enforces proper data entry, or alerts users when records are missing critical data.
- The database construction is piece of cake to modify and maintain. Workflows rarely stay the same forever, and equally such you lot will likely have to make some adjustments to your database structure in the time to come. Fortunately, a well-designed relational database ensures that whatever modifications you make to fields in i table will not adversely affect other tables.
- The data itself is easy to modify. In a similar mode, a well-designed relational database ensures that modifications made to the values in a given field in one tabular array will not adversely bear upon other fields in that table.
- Information technology's easier to observe the data that you need. With a consistent, logical database structure (that avoids indistinguishable fields and tables), it's much easier to query your database.
- Y'all can spend less time fixing your database and more fourth dimension doing other kinds of work. The all-time database is 1 that you don't accept to worry nearly.
You could build a house without offset finalizing the blueprints, but in doing so, yous might end upwardly with a house of questionable structural integrity; similarly, taking some time to think carefully about the pattern of your relational database earlier implementing information technology can relieve you a lot of trouble in the long run.
All this might seem daunting if you've only just begun learning nearly relational databases, or even if you've already built a couple of databases and encountered some challenges. Fortunately, at that place are several pattern principles you tin follow that will help you build better databases.
What is a "well-designed" database?
Then conspicuously, proficient database pattern is important when trying to build a database that works for you. But what does information technology actually mean for a database to be well-designed?
A well-designed database enforces data integrity
Data integrity refers to the overall accurateness, abyss, and consistency of the data in your database; a well-designed database maintains data integrity by implementing the processes and standards proposed during the design phase.
Information integrity includes three specific technical aspects of a relational database'southward structure:
- Entity integrity (or table-level integrity) ensures that a table has no duplicate records, and that the values of the table's primary keys are all unique and not nix.
- Domain integrity (or field-level integrity) ensures that the purpose of every field is articulate and identifiable, and that the values in each field are valid, consequent, and authentic.
- Referential integrity (or relationship-level integrity) ensures that the relationships between pairs of tables are sound, so that the records in the tables are synchronized whenever information is entered into, updated in, or deleted from either table.
A well-designed database enforces relevant business rules
Every organization does its work a little differently, and as such, each organization has its own unique requirements for its data, also known as concern rules. Some hypothetical examples might be: a video production company requires that the elapsing timestamps for its video files exist stored in milliseconds; a consumer brand requires that each product in its itemize be assigned a unique eight-character alphanumeric lawmaking; a university requires that its students sign upwardly for no more than six classes per semester.
Ideally your squad'due south database should exist able to enforce your unique business rules; this volition ensure that the data coming into your base is both accurate and useful. For example, if the academy in the previous case forgot to account for their business rules when edifice their database, a student might try to sign upward for 20 classes in a single semester—creating a mess for a database administrator to clean up later.
How to blueprint your relational database, step by step
If this all sounds unfamiliar or overwhelming, don't worry—there is a systematic process you can follow that volition ensure your relational database follows good blueprint principles, is well-suited to your organisation'southward needs, and avoids common pitfalls.
Pace 1: define your purpose and objectives
Before starting time your database design journey, it's worth taking a step dorsum and answering a very important question: "Why am I making this database?" Are you making this database in order to manage business transactions? To shop information? To solve a particular organizational problem? Any the case, information technology's worth taking the time to identify the intended purpose of the database you lot'll be creating.
Yous may even wish to piece of work together with managers, leadership, and end users to jointly write out a mission statement for your database, like: "The purpose of the Mingei International Museum database is to maintain the data for our art collection," or "Zenbooth'south database will shop all of the data for our manufacturing resource planning."
Additionally, you lot should define the objectives that the end users of the database will take: which specific tasks will the cease users need to perform in order to achieve their piece of work? Developing an explicit listing of objectives—similar "Know the status and location of each of the pieces of fine art in our collection at all times," "Produce monthly reports on customer sales," or "Maintain complete records for each of our clients"—volition help you lot determine an appropriate construction for your database every bit y'all piece of work through this design procedure.
Stride 2: analyze data requirements
Before y'all begin designing your database, you'll need to analyze your organization'southward data requirements. This might sound intimidating, simply all it means is that you'll exist assessing how your team currently does its work, and identifying what kind of data is nearly important to that piece of work. Y'all can do this by closely examining existing processes and past interviewing team members—both management and end users. Some questions to inquire as y'all deport your research:
- How is your organization currently collecting data? Are you using spreadsheets? Paper templates? Another database? Whichever of these methods you're using, find the most complete samples of piece of work that you tin can, and wait through them to notice as many different attributes as you can. For example, your editorial calendar might currently be living in a spreadsheet, and have columns for "Writer," "Due Date," "Editor," and so on.
- How is your organization currently presenting data? What kinds of reports does your arrangement apply? PDFs? Slide decks? Web pages? Carefully examine whatever types of presentations that incorporate information from your current information collection methods and employ them to place potential fields.
- How are your team members currently using data? The all-time way to determine the answers to this question is by talking to team members—both management and stop users—to identify their current data employ patterns besides equally whatever gaps in the current organisation. You lot tin ask questions similar, "What types of information are yous currently using?" and have them review the samples you collected. Importantly, these interviews tin likewise illuminate plans for the future growth of the system, which volition give you lot some insight into future information requirements.
Stride 3: create a list of entities and a list of attributes
After settling on your organization's purpose and objectives, and analyzing your data requirements, the next steps are to extract a listing of entities and a list of attributes from the body of enquiry you've compiled. In the context of relational databases, an entity is an object, person, identify, event, or thought—like "clients," "products," "projects," or "sales reps." Attributes are the defining characteristics of those entities, like "name," "quantity," "accost," "phone number," or "genre." 1 way you tin think about this is that entities are like nouns, and attributes are like the adjectives that describe those nouns.
Outset by picking out entities from your inquiry and putting them on a list. These entities will somewhen serve as a guide to assist you lot define your tables later on in the blueprint process, but they will also help yous identify the attributes necessary to create your list of fields. For instance, if you were developing a talent database for a record characterization, your entities list might look something like this:
- Artist
- Agent
- Venue
- Gigs
- etc.
Next, create a split up listing containing the relevant attributes for each of the entities you lot've identified, also every bit any other attributes that might have come up during your research. These attributes will ascertain the fields for your tables. Again, for the talent database example, your attributes list might look something like this:
- Artist Name
- Artist Phone Number
- Agent Name
- Agent Phone Number
- Agent Email Address
- Venue Proper name
- Venue Address
- Gig Dates
- etc.
Once you've collected a preliminary list of attributes, you should go through and refine them to make certain that they accurately correspond your system's advisory needs.
Tips:
- If multiple attributes have different names but actually represent the same concept, deduplicate them so there's but one. For example, if you have both "Product No." and "Production Number" on your listing, y'all should remove 1 of them.
- If multiple attributes accept similar names but actually represent different concepts, rename the attributes to be more specific. For example, you could rename two different "Name" attributes into the more specific "Artist Proper noun" and "Venue Name."
After refining your lists, it'south a good idea to review these lists that yous've compiled with some of the team members y'all interviewed to confirm that you've accounted for every necessary blazon of data. Exist sure to accept their feedback into consideration and farther refine your lists as appropriate.
Step 4: model the tables and fields
Subsequently creating your lists of entities and attributes, your task is to use those lists to design the construction of your relational database. Your list of entities will become the different tables in your base, and the list of attributes will become the fields for these tables.
Take your lists and assign each of the attributes to your tables. For case, after we finish assigning our listed attributes to our new tables, our talent management database-in-planning might look something like this:

Next, you need to selection an appropriate main key field for each table. A chief central is a major component of ensuring information integrity, as it uniquely identifies each tape inside a table and is used to establish relationships between dissimilar tables.
Each tabular array's principal key field should run across the following criteria:
- It must incorporate unique values. This will prevent you from creating duplicate records inside a tabular array.
- It cannot incorporate zippo values. A nada value is the absenteeism of a value, and as such, you cannot use a aught value to identify a tape.
- It should non be a value that will need to exist modified oft. Ideally, principal primal values will remain relatively static over time and only be changed under rare circumstances.
- Information technology should non be sensitive personal data. Social security numbers, passwords, personal health data (PHI) and other sensitive information may be unique, but should not be used as primary keys, equally doing then makes it much harder to keep this data appropriately secured in a single location.
- Ideally, information technology uses the tabular array name as part of its own name. While not strictly necessary, having the table name in the main key field name can go far easier to identify the tabular array from which the primary key field originated. For example, "Employee Proper name" would be apparently identifiable as coming from the "Employees" tabular array.
Information technology might be possible that your preliminary list of fields for a given table does non contain one single field that meets all these criteria. Nevertheless, you may exist able to combine two or more than fields to create a separate, unique field which does meet all these criteria. For example, you could combine the values in a "Given Proper noun" field and a "Surname" field to create a 3rd, calculated "Full Name" field using a chain formula.
In the consequence that this strategy still doesn't work for your purposes, yous can always manufacture a new field designated specifically for unique identification codes to serve as your primary key field. Fields similar "Production ID" or "Sales Invoice Number" are often created for this purpose.
Let's render to our talent direction database example. For the "Artists" tabular array, the "Artist name" field is already a pretty adept candidate for the chief key, as information technology'south pretty unlikely that your record characterization will sign two artists with the aforementioned proper name. We can also choice "Venue proper name" as the main central for the "Venues" table. For the other tables, however, it would probably be meliorate to make new fields that concatenate values from existing fields. In the "Agents" table, we might make a new field—"Agent total name"—that concatenates the values of the "Agent given name" and "Amanuensis surname" fields. For the "Gigs" table, an artist could perform at the same venue on multiple occasions, so we should make a new field that gives a unique proper noun to the specific combination of an creative person at a venue on a specific date. You could potentially concatenate the proper name of the creative person, the venue, and the engagement to create values like "2 Linkz at the Gotham City Metro Club, 02/xiii/2019," but that can get long and unwieldy fast. Alternatively, yous could try creating a new field—"Gig code"—with unique alphanumeric code values (like "E0023"). Whichever approach yous take is upwardly to you and your team'due south specific needs.

Pace v: establish table relationships
Once you've identified your tables, fields, and main key fields, you tin can beginning the process of linking them all together. Using your noesis gained from your prior research and conversations with other team members, you can make a preliminary attempt to define the logical relationships betwixt your unlike tables.
Relationships between tables are created by linking together primary cardinal fields and strange key fields. A foreign primal is a field in one table that references the principal cardinal of another table. For case, if you lot were designing a sales pipeline database, your "Deals" table might contain a "Sales Rep" strange key field, which would link to your "Sales Reps" table; if you were designing a content calendar database, your "Pieces" tabular array might comprise an "Editor" strange central field and an "Author" foreign cardinal field, both of which would link to your "Staff" tabular array.
To first defining the relationships between your unlike tables, identify the potential strange central fields. In an ideal relational database, foreign key fields are the but fields that should ever be duplicated, and so if you lot identify any fields that appear in multiple tables, those are likely candidates for foreign cardinal fields.
Returning to our talent agency example, we tin go through our lists of fields per table and identify the fields that share names/concepts with the primary key fields of other tables:

In that location are three types of relationships between tables:
- I-to-one relationships, in which a record in one tabular array is related to ane and but ane tape in another tabular array. An example of this might be an It squad's asset tracking database with an "Employees" table and a "Computers" table: each employee just possesses one company-owned computer, and each company-owned figurer is possessed by only 1 employee. (Annotation that one-to-one relationships are relatively uncommon.)
- One-to-many relationships, in which a record in one table can be related to one or more records in another tabular array. An case of this might be a project tracker database which contains a "Projects" table and a "Tasks" table: each project has multiple associated tasks, just each task is but associated with 1 project.
- Many-to-many relationships, in which one or more records in 1 table can be related to one or more records in another table. An case of this might be an inventory of books, which contains a "Titles" tabular array and an "Authors" table: each title volition take been written by i or more authors, and each author tin can take written one or more books.
Being able to identify the dissimilar types of relationships is helpful for modeling your arrangement'south business rules. For example, if yous specifically ascertain a relationship equally one-to-many, you can enforce a dominion that the records on the "many" side of the relationship can, indeed, only e'er exist linked to 1 record in the other table. (More on this in the next footstep.)
One action that can be very helpful for visualizing how your tables volition relate to each other is creating an entity-relationship diagram, or an ER diagram. An ER diagram is a kind of chart that uses shapes to represent your tables and lines to represent the relationships between your tables.
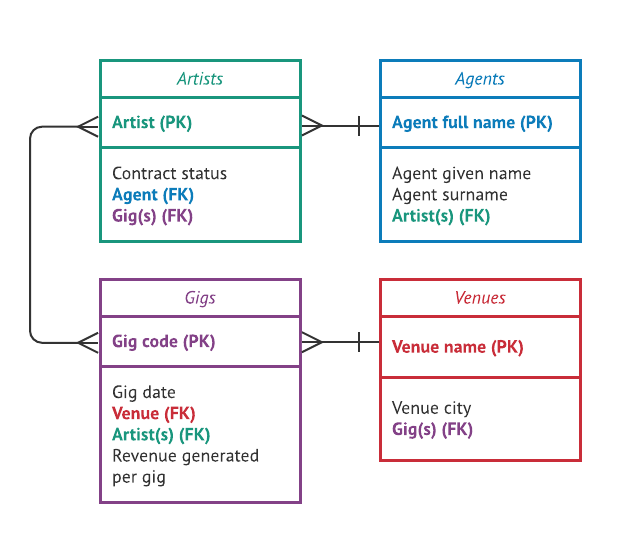
This is an example ER diagram for our talent agency database. Primary keys have been marked with "PK" and foreign keys with "FK." The different shapes at the ends of the lines notation the types of relationships between the entities: the crow's pes shape represents "many," whereas the dash represents "one." So, for example, the line between the "Artists" and "Agents" tables can be interpreted as: each creative person is associated with ane agent, but each amanuensis can exist associated with many artists.
You might be wondering why you would want to go through the attempt of establishing the relationships betwixt these tables. The main reason is that the tabular array relationships actually allow you to make logical connections between pairs of tables, which in turn allows yous to draw data from multiple tables simultaneously. Existence able to draw information from multiple tables simultaneously means that yous can make your tables more efficient and minimize redundant data. If you construct your table relationships appropriately, you can meet any data y'all need to encounter from whatever table, at any time, but you'll only ever need to enter information technology or change it in a unmarried location.
To better empathise how this might work in practice, permit'due south return in one case once more to our talent agency example. Suppose you wanted to be able to see at a glance how much revenue each creative person has generated in total beyond all their gigs. Because you've already established a relationship between the "Gigs" and the "Artists" table, you can utilize that relationship to await up data from all the relevant gig records per creative person.
To do this, you tin can create a new computed field in the "Artists" table—"Total gig revenue"—that sums the full value of "Acquirement generated per gig" for all linked records in the "Gigs" tabular array per artist. A computed field is a special kind of field that automatically generates a value using one or more than values from some other field in the database. Because the computed field updates automatically, if you ever edit a value in the "Revenue generated per gig" field or add together any new gig records for a item artist, the "Total gig revenue" field will also update automatically.
You can fifty-fifty have this ane step farther: if you lot wanted to see how much acquirement each agent has generated in total through all the artists they manage, then you could use the established relationship between the "Artists" and the "Agents" table and create a new computed field in the "Agents" table—"Artists' total gig revenue"—that sums the full value of "Total gig revenue" for all linked records in the "Artists" table per amanuensis. Since this new computed field in the "Agents" table is connected to the "Gigs" table via the "Artists" table, information technology will likewise be updated automatically if the values in the "Gigs" table alter, even though in that location is no direct relationship betwixt the "Gigs" and "Agents" tables.
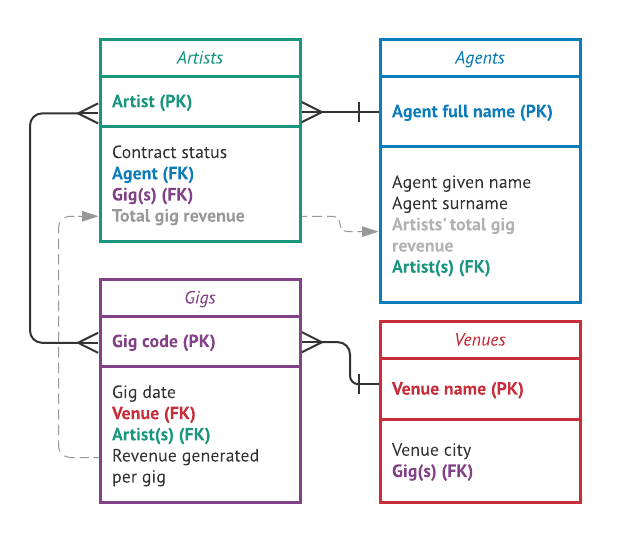
The existing table relationships permit yous to create computed fields that automatically update in all linked tables based on changes in a single location in a single table.
This sample database models the relationships described in the to a higher place ER diagram. Click through to explore how the tables chronicle to ane some other, or make a re-create of it for yourself by clicking the "Re-create base" button.
Footstep 6: plant business rules
Later fully establishing the overall structure of your database, it's fourth dimension to incorporate your organization's unique business rules into your database design. Because business rules are so closely tied to the specific means in which your organization does its work, your well-nigh valuable resources volition be, once once more, managers and end users. Consulting with them can provide invaluable insight into which constraints will exist the most impactful for your workflows.
Generally speaking, in that location are two main kinds of business rules. Field-specific business rules refer to constraints placed on specific fields. Some examples of field-specific business rules might be "Dates on our product order invoices must be displayed in the ISO format '2020-12-22,'" "Email addresses stored in the employee directory must exist valid electronic mail addresses," or "The merely valid values that can exist selected for this condition field are 'To exercise,' 'Doing,' and 'Done.'"
Relationship-specific business rules, which we briefly touched on earlier, refer to constraints placed on table relationships. Some examples of human relationship-specific business rules might exist "Each project in our video production tracker must be linked to one or more fact-checkers," or "Each line item in a client's order must exist linked to one and simply one product."
The almost thorough method of identifying and implementing your field-specific business organization rules is to systematically review each field within each table to determine which business concern rules utilize to that field. Every field will have some relevant business organization rules, fifty-fifty if those rules are every bit full general equally "Every value in the 'Employee first name' field should be a string composed of letters." In a similar style, you tin systematically review each of the relationships in your proposed database construction and assess whether or not they require any human relationship-specific business organization rules.
In the future, you will probably need to alter your existing business concern rules or add together new business rules. For example, your team might decide that "Canceled" should be a valid potential value for a task status field that currently includes merely "To practise," "Doing," and "Done" as options. Fortunately, if y'all have followed the previous steps and set up a robust underlying database structure, it should exist relatively easy to adjust your field- and human relationship-specific business organisation rules downwardly the road without having to restructure your entire database.
Step 7: check your work
You're almost done with the database pattern process—all yous need to do is perform ane final review of your database. A few questions to inquire yourself as y'all expect over every table, field, and human relationship:
- Does every type of entity have its own dedicated table?
- Are there any tables that might need to be consolidated, or, conversely, decomposed into multiple tables?
- Are there any duplicate fields in my database that are not strange keys?
- Do each of my fields accept divers specifications that friction match our arrangement'southward business rules?
- Practise the relationships between my tables make sense?
If everything looks good to you, y'all should run the final product past the cease users and managers who will exist interacting with the database. If they're satisfied with the end result, so rejoice! Be proud of your new, structurally sound database.
Sign upwards for Airtable for gratuitous

How To Set Up A Relational Database,
Source: https://blog.airtable.com/how-to-design-an-effective-relational-database/
Posted by: nalleyslarpon.blogspot.com
0 Response to "How To Set Up A Relational Database"
Post a Comment